How to Tokenize Complex Strings with Lexmachine
This article is about using lexmachine
to tokenize strings (split up into component parts) in the Go (golang)
programming language. If you find yourself processing a complex file format or
network protocol this article will walk you through how to use lexmachine to
process both accurately and quickly. If you need more help after reading this
article take a look at the
documentation, a
tutorial,
or an explainer
article
on how it all works.
What is string tokenization?
String tokenization takes a piece of text and splits it into categorized
substrings. When conducted as part of parsing or compiling a programming
language it may also be called lexical analysis. Depending on the kind of text
being processed splitting it up might be very simple or extremely complicated.
For instance, some simple text formats (such as basic CSV or TSV files) separate
each record by newline characters (\n or ASCII 0x0A). At the other end of
the spectrum, natural language (such as English text) may be very difficult to
correctly tokenize.
Let's look at a quick example of tokenizing an English sentence.
Mary had a little lamb and its fleece was white as snow.
Each word will be a separate token. A token is a pair made up of the lexeme (or substring) and the token type (or category). When tokenizing English, often the token type will be the part of speech.
Mary had a little lamb and ...
<Proper Noun> <Verb> <Article> <Adjetive> <Noun> <Conjunction> ...
Tokenizing English is very difficult in general because determining the part of speech of a particular word is not always obvious. The same word can play multiple semantic roles in a sentence. Humans consider the sentence in its entirety when determining the parts of speech for each word. This allows us to "noun verbs" and "verb nouns."
String tokenization as part of parsing
There are many common applications of tokenization which are not as difficult as assigning parts of speech to words in English. For instance, computer languages, configuration files, log files, network protocols, data interchange formats, etc... are all easy to tokenize. In these applications (as with natural language), tokenization is the first step in parsing or compilation and is called lexical analysis.
Modern compilers are designed as a "pipeline" or series of steps (called passes) which operate over a program. They take the source code and transform it step by step into the desired output (machine code, assembly, another programming language). Breaking compilation into steps simplifies each stage and makes the individual passes reusable. The start of the pipeline is shown in Figure 1.
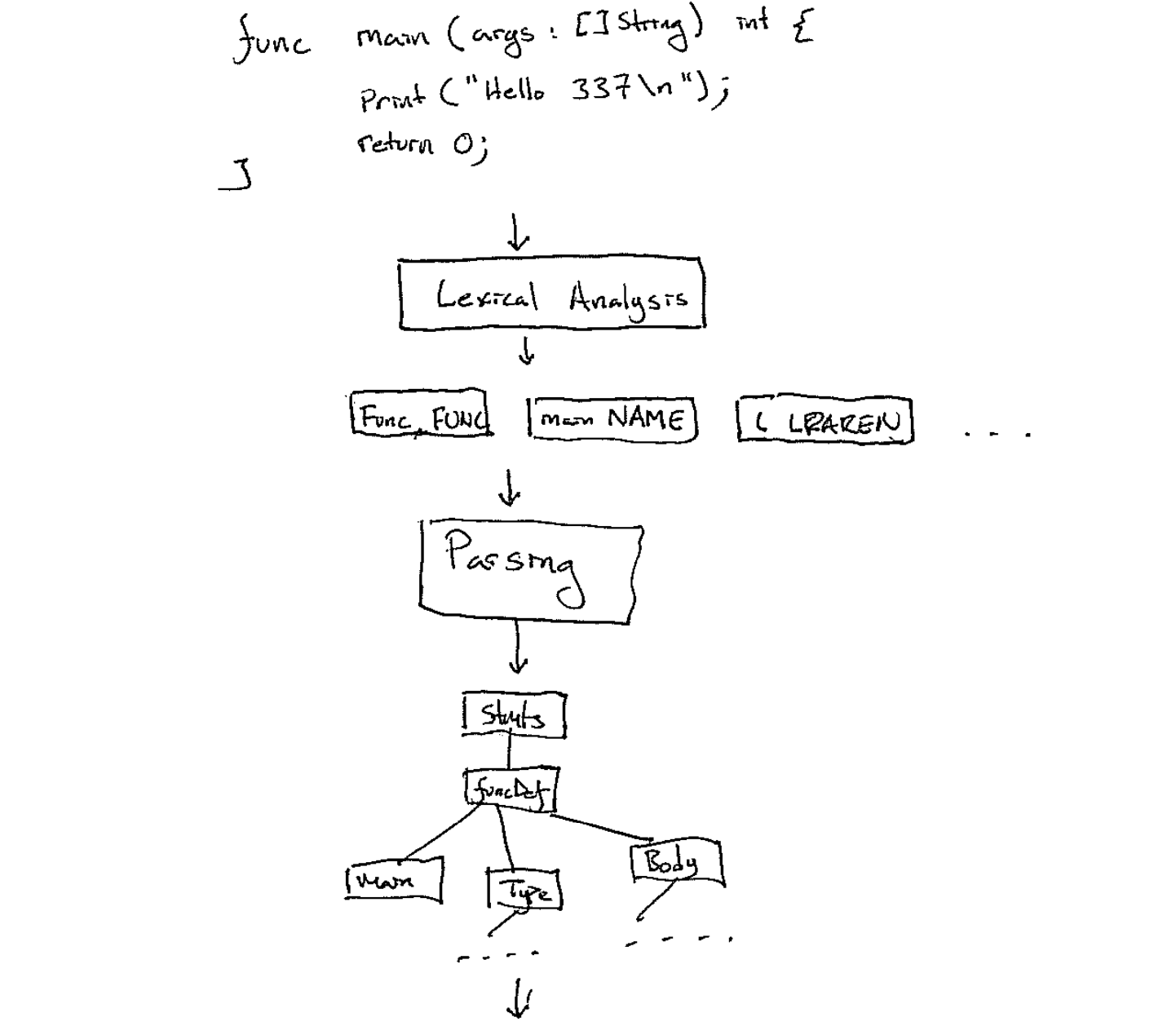
A compiler starts with source code and then preforms lexical analysis to split the code up into *tokens*. Then, the *parser* transforms that stream or list of tokens into a structured format (often an Abstract Syntax Tree).
But why tokenize before parsing? Surely, the parser could operate on the bytes of the source code rather than on a list of tokens. Some parsers do operate directly on the bytes. However, the parser can be simplified and made shorter and often more robust by defining it over tokens rather than bytes.
Consider the following, programming languages often have keywords: func,
return, if. They also have "identifiers" or names. The keywords are set
aside as special names and are treated by a parser the same way other names are
treated as they often denote the start of special syntactic regions. In this
way, they really operate in a similar manner to punctuation in written English.
However, since keywords would be valid names if they were not reserved special care must be taken in a parser which operates on bytes directly not to accidentally classify a keyword as a name. Parsers which work on tokens rather than bytes can ignore this problem as it is handled at the lexical analysis stage.
Processing a custom configuration file format
As a motivating example for why you might need to perform a tokenization
operation in your daily life as a programmer let's take a look at processing a
customer configuration file format. Linux has a library libsensor which allows
it to read and understand the output of hardware sensors (such as CPU
temperature probes). It has a custom configuration file format,
sensors.conf, which describes how
Linux should translate the raw readings hardware monitoring chips to real-world
values -- such as voltage and temperature. The first part of my laptop's
sensors.conf file begins with the following:
# It is recommended not to modify this file, but to drop your local
# changes in /etc/sensors.d/. File with names that start with a dot
# are ignored.
chip "lm78-*" "lm79-*" "lm80-*" "lm96080-*"
label temp1 "M/B Temp"
chip "w83792d-*"
label in0 "VcoreA"
label in1 "VcoreB"
label in6 "+5V"
label in7 "5VSB"
label in8 "Vbat"
set in6_min 5.0 * 0.90
set in6_max 5.0 * 1.10
set in7_min 5.0 * 0.90
set in7_max 5.0 * 1.10
set in8_min 3.0 * 0.90
set in8_max 3.0 * 1.10
Let's pretend we want to extract some information from sensors.conf files. For
instance, maybe we want to know for each chip what labels have been defined.
Straightforward enough and definitely doable "by hand" if necessary but much
easier if the file is preprocessed to pull out the tokens:
Type | Lexeme
-------------------
COMMENT | # It is recommended not to modify this file, but to drop your local
COMMENT | # changes in /etc/sensors.d/. File with names that start with a dot
COMMENT | # are ignored.
CHIP | chip
NAME | "lm78-*"
NAME | "lm78-*"
NAME | "lm79-*"
NAME | "lm80-*"
NAME | "lm96080-*"
LABEL | label
NAME | temp1
NAME | "M/B Temp"
CHIP | chip
NAME | "w83792d-*"
...
SET | set
NAME | in8_max
FLOAT | 3.0
STAR | *
FLOAT | 1.10
According to the man page the chip and label statements have the following structure (other bits left out):
chip Statement
A chip statement selects for which chips all following compute, label, ignore and set statements are meant for.
label Statement
A label statement describes how a feature should be called.
chip NAME-LIST
label NAME NAMEA NAME is a string. If it only contains letters, digits and underscores, it does not have to be quoted; in all other cases, you must use double quotes around it. Within quotes, you can use the normal escape-codes from C.
A NAME-LIST is one or more NAME items behind each other, separated by whitespace.
So to find all of the labeled "features" of a chip we need to do two things.
First, find a chip statement and collect all the names associated with it.
These names are actually patterns which match multiple chips but we will ignore
that for this example. Second, collect all the label statements (and the two
associated names). The labels go with the chips which immediately proceed them.
To implement the above idea we are going to use lexmachine to construct a lexer (or tokenizer) which split up the file into the appropriate tokens.
Defining a lexer with lexmachine
A lexer (or tokenizer) is defined by a set of categories (token types) which
are defined by patterns. The patterns (in a traditional lexer) are expressed
as regular
expressions. As a
quick and incomplete review, regular expressions (regex) are a "pattern" which
describe a set of strings. A regex is made up of characters (a, b, 0, @,
...) which combine with the operators: concatenation abc, alternation a|b,
grouping a(b|c)d, and repetition a*. Some examples:
abcmatches {"abc"}a|bmatches {"a","b"}a(b|c)dmatches {"abd","acd"}a*matches {"","a","aa", ...}a(b(c|d))*matches {"a","abc","abd","abcbc","abcbd", ...}
A fairly close reading of the man
page for sensors.conf gives the
following regular expressions to tokenize the file. (Note: [] define
character classes
which express a number of alternative characters to match)
AT:@PLUS:\+STAR:\*DASH:-SLASH:/BACKSLASH:\\CARROT:\^BACKTICK:`COMMA:,LPAREN:\(RPAREN:\)BUS:busCHIP:chipLABEL:labelCOMPUTE:computeIGNORE:ignoreSET:setNUMBER:[0-9]*\.?[0-9]+COMMENT:#[^\n]*SPACE:\s+NAME:[a-zA-Z_][a-zA-Z0-9_]*NAME:"((\\\\)|(\\.)|([^"\\]))*"
With these regular expressions in hand let's define a lexer using
lexmachine and use it to tokenize an
example sensors.conf.
Aside, can't we just use regexp?
A lexical analysis engine is very similar to a standard regular expression engine. However, the problem which regular expression engines solve (matching whole strings or finding patterns inside of strings) is slightly different than the lexial analysis problem. You could implement a lexical analyzer with the
regexppackage but it would be much slower than lexmachine. Lexical analysis engines are fast because they use the same theoretical framework as is used to implement regular expression engines with the following adjustments:
- Prefixes of a string are matched
- All patterns are matched at the same time
- The pattern which matches the longest prefix wins
- In case of ties, the pattern with the highest precedence wins
Constructing a *lexmachine.Lexer
Importing the packages
import (
"github.com/timtadh/lexmachine"
"github.com/timtadh/lexmachine/machines"
)
Defining the tokens types
There are many ways to represent the token types (categories). In this example,
the names of the types are defined as a list of strings. The types themselves
(ids) will be the index of the names. An init function is used to construct
a reverse mapping from name to id.
var tokens = []string{
"AT", "PLUS", "STAR", "DASH", "SLASH", "BACKSLASH", "CARROT", "BACKTICK",
"COMMA", "LPAREN", "RPAREN", "BUS", "COMPUTE", "CHIP", "IGNORE", "LABEL",
"SET", "NUMBER", "NAME", "COMMENT", "SPACE",
}
var tokmap map[string]int
func init() {
tokmap = make(map[string]int)
for id, name := range tokens {
tokmap[name] = id
}
}
Constructing a new lexer object
lexer := lexmachine.NewLexer()
Adding a single pattern
Patterns are added using the
lexer.Add method.
Let's add the pattern for the chip keyword:
lexer.Add([]byte(`chip`), func(s *lexmachine.Scanner, m *machines.Match) (interface{}, error) {
return 0, nil
})
The Add method takes two arguments. The first is the regular expression and
the second is the lexing action function. The action is called on pattern
discovery. This action typically takes a low-level
*machines.Match
object and turns it into a token representation of your (the user's) choice.
For users who do not have strict requirements for how tokens are represented
the *lexmachine.Token
object provides a useful implementation. *lexmachine.Scanner has a utility
method for constructing the tokens which helps us write a simple getToken
action:
func getToken(tokenType int) lexmachine.Action {
return func(s *lexmachine.Scanner, m *machines.Match) (interface{}, error) {
return s.Token(tokenType, string(m.Bytes), m), nil
}
}
Adding all the patterns
func newLexer() *lexmachine.Lexer {
lexer := lexmachine.NewLexer()
lexer.Add([]byte("@"), getToken(tokmap["AT"]))
lexer.Add([]byte(`\+`), getToken(tokmap["PLUS"]))
lexer.Add([]byte(`\*`), getToken(tokmap["STAR"]))
lexer.Add([]byte("-"), getToken(tokmap["DASH"]))
lexer.Add([]byte("/"), getToken(tokmap["SLASH"]))
lexer.Add([]byte("\\"), getToken(tokmap["BACKSLASH"]))
lexer.Add([]byte(`\^`), getToken(tokmap["CARROT"]))
lexer.Add([]byte("`"), getToken(tokmap["BACKTICK"]))
lexer.Add([]byte(","), getToken(tokmap["COMMA"]))
lexer.Add([]byte(`\(`), getToken(tokmap["LPAREN"]))
lexer.Add([]byte(`\)`), getToken(tokmap["RPAREN"]))
lexer.Add([]byte("bus"), getToken(tokmap["BUS"]))
lexer.Add([]byte("chip"), getToken(tokmap["CHIP"]))
lexer.Add([]byte("label"), getToken(tokmap["LABEL"]))
lexer.Add([]byte("compute"), getToken(tokmap["COMPUTE"]))
lexer.Add([]byte("ignore"), getToken(tokmap["IGNORE"]))
lexer.Add([]byte("set"), getToken(tokmap["SET"]))
lexer.Add([]byte(`[0-9]*\.?[0-9]+`), getToken(tokmap["NUMBER"]))
lexer.Add([]byte(`[a-zA-Z_][a-zA-Z0-9_]*`), getToken(tokmap["NAME"]))
lexer.Add([]byte(`"((\\.)|([^"\\]))*"`), func(s *lexmachine.Scanner, m *machines.Match) (interface{}, error) {
return s.Token(tokmap["NAME"], string(m.Bytes[1:len(m.Bytes)-1]), m), nil
})
lexer.Add([]byte(`#[^\n]*`), getToken(tokmap["COMMENT"]))
lexer.Add([]byte(`( |\t|\f)+`), getToken(tokmap["SPACE"]))
lexer.Add([]byte(`\\\n`), getToken(tokmap["SPACE"]))
lexer.Add([]byte(`\n|\r|\n\r`), getToken(tokmap["NEWLINE"]))
err := lexer.Compile()
if err != nil {
panic(err)
}
return lexer
}
Skipping a pattern
Sometimes it is advantageous to not emit tokens for certain patterns and to
instead skip them. Commonly this occurs for whitespace and comments. To skip a
pattern simply have the action return nil, nil:
func skip(scan *Scanner, match *machines.Match) (interface{}, error) {
return nil, nil
}
lexer.Add([]byte(`\s+`), skip) // skip whitespace
lexer.Add([]byte(`#[^\n]*`), skip) // skip comments
In our example for sensors.conf we only care about the keywords and the NAME
tokens. Let's skip the rest:
func newLexer() *lexmachine.Lexer {
lexer := lexmachine.NewLexer()
lexer.Add([]byte(`@`), skip)
lexer.Add([]byte(`\+`), skip)
lexer.Add([]byte(`\*`), skip)
lexer.Add([]byte("-"), skip)
lexer.Add([]byte("/"), skip)
lexer.Add([]byte("\\"), skip)
lexer.Add([]byte(`\^`), skip)
lexer.Add([]byte("`"), skip)
lexer.Add([]byte(","), skip)
lexer.Add([]byte(`\(`), skip)
lexer.Add([]byte(`\)`), skip)
lexer.Add([]byte("bus"), skip)
lexer.Add([]byte("chip"), getToken(tokmap["CHIP"]))
lexer.Add([]byte("label"), getToken(tokmap["LABEL"]))
lexer.Add([]byte("compute"), skip)
lexer.Add([]byte("ignore"), skip)
lexer.Add([]byte("set"), skip)
lexer.Add([]byte(`[0-9]*\.?[0-9]+`), skip)
lexer.Add([]byte(`[a-zA-Z_][a-zA-Z0-9_]*`), getToken(tokmap["NAME"]))
lexer.Add([]byte(`"((\\.)|([^"\\]))*"`), func(s *lexmachine.Scanner, m *machines.Match) (interface{}, error) {
return s.Token(tokmap["NAME"], string(m.Bytes[1:len(m.Bytes)-1]), m), nil
})
lexer.Add([]byte(`#[^\n]*`), skip)
lexer.Add([]byte(`( |\t|\f)+`), skip)
lexer.Add([]byte(`\\\n`), skip)
lexer.Add([]byte(`\n|\r|\n\r`), getToken(tokmap["NEWLINE"]))
err := lexer.Compile()
if err != nil {
panic(err)
}
return lexer
}
Constructing the lexer exactly once
The lexer should be constructed and compiled exactly once: on program startup (unless the regular expressions are defined dynamically). This ensures that you only pay the compilation costs at program startup and get the maximum benefit from the efficient DFA representation produced by compilation.
var lexer *lexmachine.Lexer
func init() {
lexer = newLexer()
}
Example tokenization
scanner, err := lexer.Scanner([]byte("chip chip1 chip2 label name value"))
if err != nil {
panic(err)
}
for tk, err, eof := scanner.Next(); !eof; tk, err, eof = scanner.Next() {
if err != nil {
panic(err)
}
token := tk.(*lexmachine.Token)
fmt.Printf("%-7v | %-25q | %v:%v-%v:%v\n",
tokens[token.Type],
token.Value.(string),
token.StartLine,
token.StartColumn,
token.EndLine,
token.EndColumn)
}
Output
CHIP | "chip" | 1:1-1:4
NAME | "chip1" | 1:6-1:10
NAME | "chip2" | 1:12-1:16
LABEL | "label" | 1:18-1:22
NAME | "name" | 1:24-1:27
NAME | "value" | 1:29-1:33
For more details on the scanner interface consult the narrative documentation.
Associating labels with chips
There are several ways we could approach taking the output of the scanner
above and using it to find what labels go with what chip names. In this example,
a very simple, short, but ugly method is going to be demonstrated. Inside of the
scanning for-loop a simple state machine will track what the current statement a
particular NAME token belongs to. If it belongs to a chip statement or a
label statement it is appropriately associated. Finally, whenever a new CHIP
token is encountered the current buffer of labels are associated with the
previous chip statement.
func printChipLabels(text []byte) error {
scanner, err := lexer.Scanner(text)
if err != nil {
return err
}
order := make([]string, 0, 10)
chipLabels := make(map[string][]string)
curChips := make([]string, 0, 10)
curLabels := make([]string, 0, 10)
curLabel := make([]string, 0, 2)
state := "none"
addChips := func() {
for _, chip := range curChips {
if _, has := chipLabels[chip]; !has {
order = append(order, chip)
}
chipLabels[chip] = append(chipLabels[chip], curLabels...)
}
curChips = make([]string, 0, 10)
curLabels = make([]string, 0, 10)
curLabel = make([]string, 0, 2)
}
for tk, err, eof := scanner.Next(); !eof; tk, err, eof = scanner.Next() {
if err != nil {
return err
}
token := tk.(*lexmachine.Token)
switch token.Type {
case tokmap["CHIP"]:
addChips()
state = "chip"
case tokmap["LABEL"]:
state = "label"
case tokmap["NAME"]:
switch state {
case "chip":
curChips = append(curChips, token.Value.(string))
case "label":
curLabel = append(curLabel, token.Value.(string))
if len(curLabel) >= 2 {
curLabels = append(curLabels, strings.Join(curLabel, ":"))
curLabel = make([]string, 0, 2)
}
}
case tokmap["NEWLINE"]:
state = "none"
}
}
addChips() // close the final chip statement
for _, chip := range order {
fmt.Printf("chip %v: %v\n", chip, strings.Join(chipLabels[chip], ", "))
}
return nil
}
Output for the sensors.conf file on my machine:
chip lm78-*: temp1:M/B Temp
chip lm79-*: temp1:M/B Temp
chip lm80-*: temp1:M/B Temp
chip lm96080-*: temp1:M/B Temp
chip w83792d-*: in0:VcoreA, in1:VcoreB, in6:+5V, in7:5VSB, in8:Vbat
chip w83793-*: in0:VcoreA, in1:VcoreB, in7:+5V, in8:5VSB, in9:Vbat
chip w83795g-*: in12:+3.3V, in13:3VSB, in14:Vbat
chip w83795adg-*: in12:+3.3V, in13:3VSB, in14:Vbat
chip via686a-*: in0:Vcore, in2:+3.3V, in3:+5V, in4:+12V
chip adm1025-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, in5:VCC, temp1:CPU Temp, temp2:M/B Temp
chip ne1619-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, in5:VCC, temp1:CPU Temp, temp2:M/B Temp
chip lm87-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp1:M/B Temp, temp2:CPU Temp
chip adm1024-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp1:M/B Temp, temp2:CPU Temp
chip it87-*: in8:Vbat
chip it8712-*: in8:Vbat
chip it8716-*: in8:Vbat
chip it8718-*: in8:Vbat
chip it8720-*: in8:Vbat
chip fscpos-*: in0:+12V, in1:+5V, in2:Vbat, temp1:CPU Temp, temp2:M/B Temp, temp3:Aux Temp
chip fscher-*: in0:+12V, in1:+5V, in2:Vbat, temp1:CPU Temp, temp2:M/B Temp, temp3:Aux Temp
chip fscscy-*: in0:+12V, in1:+5V, in2:+3.3V, temp1:CPU0 Temp, temp2:CPU1 Temp, temp3:M/B Temp, temp4:Aux Temp
chip fschds-*: temp1:CPU Temp, temp2:Super I/O Temp, temp3:System Temp, an1:PSU Fan, an2:CPU Fan, an3:System FAN2, an4:System FAN3, an5:System FAN4, in0:+12V, in1:+5V, in2:Vbat
chip fscsyl-*: temp1:CPU Temp, temp4:Super I/O Temp, temp5:Northbridge Temp, an1:CPU Fan, an2:System FAN2, an3:System FAN3, an4:System FAN4, an7:PSU Fan, in0:+12V, in1:+5V, in2:Vbat, in3:+3.3V, in5:+3.3V-Aux
chip vt1211-*: in5:+3.3V, temp2:SIO Temp
chip vt8231-*: in5:+3.3V
chip smsc47m192-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, in5:VCC, temp1:SIO Temp
chip lm85-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip lm85b-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip lm85c-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip adm1027-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip adt7463-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip adt7468-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip emc6d100-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip emc6d102-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip emc6d103-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip emc6d103s-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip emc6w201-*: in2:+3.3V, in3:+5V, temp6:M/B Temp
chip pc87365-*: in7:3VSB, in8:VDD, in9:Vbat, in10:AVDD, temp3:SIO Temp
chip pc87366-*: in7:3VSB, in8:VDD, in9:Vbat, in10:AVDD, temp3:SIO Temp
chip adm1030-*: temp1:M/B Temp
chip adm1031-*: temp1:M/B Temp
chip w83627thf-*: in3:+5V, in7:5VSB, in8:Vbat
chip w83627ehf-*: in0:Vcore, in2:AVCC, in3:+3.3V, in7:3VSB, in8:Vbat
chip w83627dhg-*: in0:Vcore, in2:AVCC, in3:+3.3V, in7:3VSB, in8:Vbat
chip w83667hg-*: in0:Vcore, in2:AVCC, in3:+3.3V, in7:3VSB, in8:Vbat
chip nct6775-*: in0:Vcore, in2:AVCC, in3:+3.3V, in7:3VSB, in8:Vbat
chip nct6776-*: in0:Vcore, in2:AVCC, in3:+3.3V, in7:3VSB, in8:Vbat
chip w83627uhg-*: in2:AVCC, in3:+5V, in7:5VSB, in8:Vbat
chip f71805f-*: in0:+3.3V
chip f71872f-*: in0:+3.3V, in9:Vbat, in10:3VSB
chip k8temp-*: temp1:Core0 Temp, temp2:Core0 Temp, temp3:Core1 Temp, temp4:Core1 Temp
chip dme1737-*: in0:5VSB, in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, in5:3VSB, in6:Vbat, temp2:SIO Temp
chip sch311x-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, in5:3VSB, in6:Vbat, temp2:SIO Temp
chip sch5027-*: in0:5VSB, in1:Vcore, in2:+3.3V, in5:3VSB, in6:Vbat, temp2:SIO Temp
chip sch5127-*: in2:+3.3V, in5:3VSB, in6:Vbat
chip f71808e-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71808a-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71862fg-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71869-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71869a-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71882fg-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71889fg-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71889ed-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71889a-*: in0:+3.3V, in7:3VSB, in8:Vbat
chip f71858fg-*: in0:+3.3V, in1:3VSB, in2:Vbat
chip f8000-*: in0:+3.3V, in1:3VSB, in2:Vbat
chip f81865f-*: in0:+3.3V, in5:3VSB, in6:Vbat
chip adt7473-*: in2:+3.3V, temp2:Board Temp
chip adt7475-*: in2:+3.3V, temp2:Board Temp
chip adt7476-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
chip adt7490-*: in1:Vcore, in2:+3.3V, in3:+5V, in4:+12V, temp2:M/B Temp
Conclusion
This article presented lexmachine a library that helps you break up complex strings into their component parts safely, reliably, and quickly. To learn more visit the project page, browse the documentation, look at another tutorial, or read an explainer article on how it all works.